Improve Apex Code Quality Using SFDX Scanner
Learn how to improve Apex code quality and security with SFDX Scanner. Discover how to install, run static analysis, and integrate SFDX Scanner into your CI/CD pipeline using GitHub Actions.
SFDX Scanner is a plugin to automate code scanning for Apex development. Using a plugin like SFDX scanner increases code quality by flagging potential vulnerabilities in the code. Using the SFDX scanner plugin can be automated into your development pipeline to further improve code quality. SFDX Scanner is an open sourceproject that can help you automate code reviews, and prepare your code for an AppExchange security review.
What is SFDX Scanner
SFDX Scanner is a plugin for Salesforce developers. SFDX scanner does static analysis on apex code, lightning web components (LWC), and aura components. The static analysis performed provides details on:
- Security vulnerabilities
- Performance bottlenecks
- Field Level Security
- Styling Issues
Using a static analysis helps reduces errors in code, and improve readability.
What Languages does SFDX Scanner Analyze?
SFDX Scanner analysis all languages and is language agnostic. Additionally, it is not required to use the SFDX folder structure to use SFDX Scanner. There are multiple engines that analyze code, including:
- PMD
- CPD
- ESLint
- Salesforce Graph Engine
Each engine analyzes different languages and aspects of your code repository.
How to Install SFDX Scanner
Installing SFDX Scanner is easy with the SFDX plugin format. After SFDX is installed on your local machine, run the following:
sfdx plugins install @salesforce/sfdx-scannerTo confirm the plugin is installed, you can run the following:
sfdx scanner --helpHow to Run SFDX Scanner
SFDX Scanner will run static analysis on your repository supplied. From the base of your SFDX project, run:
sfdx scanner run --target "." -f csv -o scanner_results.csvNote the parameters, where:
- -t (--target) - The base folder of your sfdx code
- -f (--format) - The output format of the scanner results
- -o (--output) - The output file of the scanner results.
Controlling SFDX Scanner Rules
Given the two main engines, PMD and ESLint, we can pass config files with the following parameters:
--pmdconfig--tsconfig
We can pass file paths for rule configurations that are ran within the scanner. See the example PMD config, pmd-ruleset.xml:
<?xml version="1.0"?>
<ruleset name="CI/CD Rules"
xmlns="http://pmd.sourceforge.net/ruleset/2.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://pmd.sourceforge.net/ruleset/2.0.0 https://pmd.sourceforge.io/ruleset_2_0_0.xsd">
<description>
CI/CD PMD Ruleset
</description>
<rule ref="category/apex/bestpractices.xml">
</rule>
<rule ref="category/apex/codestyle.xml">
</rule>
<rule ref="category/apex/design.xml">
</rule>
<rule ref="category/apex/documentation.xml">
</rule>
<rule ref="category/apex/errorprone.xml">
</rule>
<rule ref="category/apex/performance.xml">
</rule>
<rule ref="category/apex/security.xml">
</rule>
</ruleset>While this is a way of controlling which rules are run, and removing erroneous errors, it is better to use warning suppression tactically.
Understanding the SFDX Scanner Output
With the scanner results, we can determine areas of improvement for our code, broken down into the following categories:
- Design
- Security
- Error Prone
- Performance
- Best Practices
- Documentation
Each category has individual rules associated with them. For example, a CRUD violation is within the Security category. To get a full list of the rules in SFDX Scanner, run the following snippet:
sfdx scanner rule listEach rule has a priority associated with them. It is recommended to normalize security using the --normalize-severity flag. This normalized severity is a scale of 1 to 3, where 1 is the highest priority. An example priority 1 issue is the file not compiling. An example priority 3 would be a hard-coded ID.
Writing Custom Rules for SFDX Scanner
Additionally, custom rules can be created for SFDX Scanner. Because SFDX Scanner uses PMD, a static analysis engine, the same custom rule format is required. This means custom rules can be written in XPath or Java. To learn more about custom SFDX Scanner rules, check out PMD's documentation.
What Are Common SFDX Scanner Errors
Understanding common errors developers make is important to flag within code reviews. Below are common errors and how they are flagged within SFDX Scanner:
| Error | Severity | Category |
|---|---|---|
| DML in for-loop | 3 | Performance |
| File Doesn't compile | 1 | Scanner internal |
| SQL in for-loop | 3 | Performance |
| Logic in Trigger | 1 | Best practices |
| Hardcoding Id | 3 | Error Prone |
How to use Warning Suppression in SFDX Scanner
Warning suppression is the best way of handling false positives for SFDX Scanner errors. For example, look at the wrapper class for the a Named Credential implementation with QIME:
public class BearerTokenWrapper{
public Integer x_refresh_token_expires_in;
public String refresh_token {get; set;}
public String access_token {get;set;}
public Integer expires_in;
public String token_type;
}This class fails a lot of styling checks that are preferred for Java-like languages. Running SFDX Scanner on this class gives the following errors:
| Rule | Description | Category |
|---|---|---|
| VariableNamingConventions | Only variables that are final should contain underscores (except for underscores in standard prefix/suffix), 'x_refresh_token_expires_in' is not final. | Code Style |
| FieldNamingConventions | The instance field name 'x_refresh_token_expires_in' doesn't match '[a-z][a-zA-Z0-9]*' | Code Style |
| ApexDoc | Missing ApexDoc comment | Documentation |
| VariableNamingConventions | Only variables that are final should contain underscores (except for underscores in standard prefix/suffix), 'refresh_token' is not final. | Code Style |
| PropertyNamingConventions | The instance property name 'refresh_token' doesn't match '[a-z][a-zA-Z0-9]*' | Code Style |
| ApexDoc | Missing ApexDoc comment | Documentation |
| VariableNamingConventions | Only variables that are final should contain underscores (except for underscores in standard prefix/suffix), 'access_token' is not final. | Code Style |
| PropertyNamingConventions | The instance property name 'access_token' doesn't match '[a-z][a-zA-Z0-9]*' | Code Style |
| FieldDeclarationsShouldBeAtStart | Field declaration for 'expires_in' should be before method declarations in its class | Code Style |
| VariableNamingConventions | Only variables that are final should contain underscores (except for underscores in standard prefix/suffix), 'expires_in' is not final. | Code Style |
| FieldNamingConventions | The instance field name 'expires_in' doesn't match '[a-z][a-zA-Z0-9]*' | Code Style |
| FieldDeclarationsShouldBeAtStart | Field declaration for 'token_type' should be before method declarations in its class | Code Style |
| VariableNamingConventions | Only variables that are final should contain underscores (except for underscores in standard prefix/suffix), 'token_type' is not final. | Code Style |
| FieldNamingConventions | The instance field name 'token_type' doesn't match '[a-z][a-zA-Z0-9]*' | Code Style |
There are a lot of errors for styling and variable name choice. This code was written to parse Quickbooks's API information, so this field naming convention will be required. Instead of disabling all Documentation rules, we can use the @SuppressWarnings notation to ignore SFDX Scanner warnings for this class.
To ignore all warnings on an Apex class, we can annotate the class like so:
@SuppressWarnings('PMD')
public class BearerTokenWrapper{
...
}While this works great, this hamstrings future potential error checks because we suppress ALL warnings from the PMD engine. We can narrow down the rules using dot notation like so:
@SuppressWarnings('PMD.PropertyNamingConventions')
public class BearerTokenWrapper{
...
}But in this case, we want to ignore multiple rules. This can be achieved with comma deliminated rules within the quotes like so:
@SuppressWarnings('PMD.PropertyNamingConventions, PMD.VariableNamingConventions, PMD.FieldNamingConventions')
public class BearerTokenWrapper{
...
}And with this warning suppression, there are no more errors from SFDX Scanner when running static analysis.
How use SFDX Scanner with Github Actions
Turning the SFDX Scanner command into a Github Action for your CI/CD pipeline is easy and straight forward. Inside your repo, create the following folders to hold the Github Action:
.github/workflows
Inside the workflow folder, create the file scanner.yml with the following content:
name: Run SFDX Scanner
on:
push:
paths:
- force-app/**
jobs:
scan-files:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v3
- name: Install SFDX CLI and Scanner
run: |
npm install --global sfdx-cli
sfdx --version
sfdx plugins install @salesforce/sfdx-scanner
- name: Apex static analysis
run: |
sfdx scanner run --target "force-app" -f junitThis GitHub Action will run static analysis on the code every time code is committed to GitHub. The results for each run can be seen within your GitHub repository.
How to Use SFDX Scanner Run DFA
In version 3.x, SFDX Scanner introduced DFA scanning (Data Flow Analysis). Data flow analysis is a technique to see how information (data) inside code is accessed and modified. Inside the Salesforce ecosystem, DFA is a good way to understand FLS violations within Apex code. Below is a diagram of how SFDX Scanner DFA works:
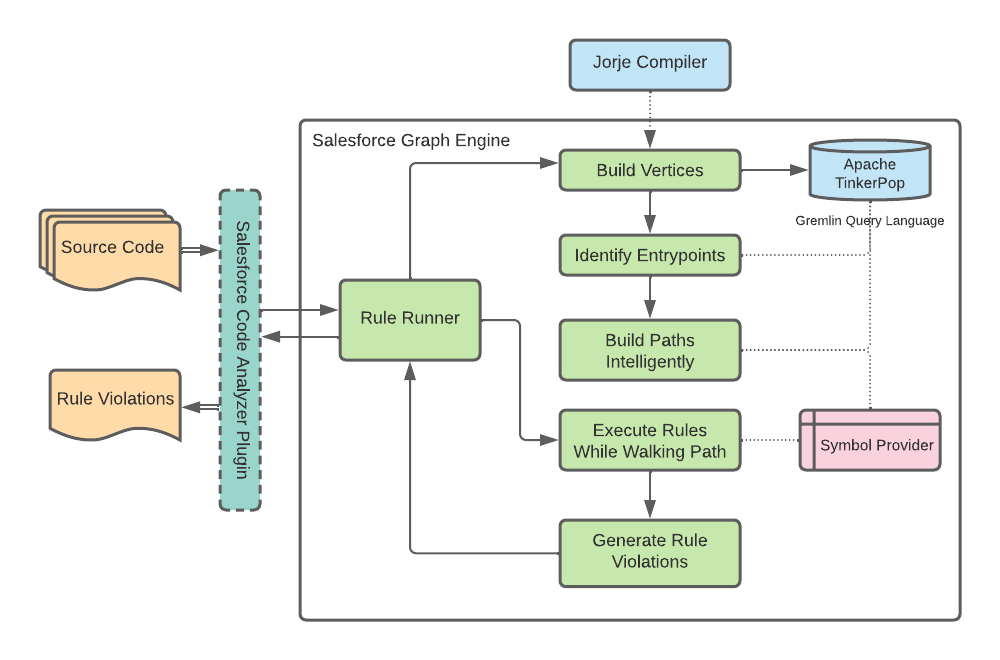
At the time of writing, FLS (Field Level Security) violations are the only rules checked during data flow analysis.
To run DFA on your Salesforce code, run the following snippet:
sfdx scanner run dfa --projectdir force-app -t force-app --outfile dfa.csvWhere --projectdir is the directory of the code that needs to be scanned, and -t is the target file for analysis. Note that the target can be a directory, or a file.
Running out of Memory when Using sfdx scanner run dfa
Due to the nature of how data flow analysis is performed, it is extremely taxing on system memory. It may require 20 GB of Ram to run DFA on production environment code. With this in mind, the two main recommendations for reducing system load are:
- Running the target as a single file or subset of apex classes
- Increasing memory allocated to DFA You can learn more about how to perform these in the SFDX Scanner Documentation.
How to use SFDX Scanner Run DFA in GitHub Actions
Like previously mentioned, DFA and the Salesforce Graph engine are extremely taxing on a system's memory. At the current time, I do not recommend adding any DFA to an automated pipeline unless you have full control over the automation system.
Conclusion
With SFDX Scanner, you can perform static analysis on your Apex code repository. Additionally, this process can be automated and added to your GitHub Action pipeline. Using static analysis and data flow analysis are both great tools to reduce security issues and increase code performance.
